Жаропонижающие средства для детей назначаются педиатром. Но бывают ситуации неотложной помощи при лихорадке, когда ребенку нужно дать лекарство немедленно. Тогда родители берут на себя ответственность и применяют жаропонижающие препараты. Что разрешено давать детям грудного возраста? Чем можно сбить температуру у детей постарше? Какие лекарства самые безопасные?
Определение 10.1 Некоторый нетерминальный символ А контекстно-свободной грамматики G = (N, P, S) называется рекурсивным, если существует вывод А + А для некоторых и. Если при этом =, то А называется леворекурсивным. Аналогично, если =, то А называется праворекурсивным. Грамматика, имеющая хотя бы один леворекурсивный нетерминальный символ, называется леворекурсивной. Грамматика, в которой все нетерминальные символы, кроме, быть может, начального символа, рекурсивные, называется рекурсивной.
Заметим, что для рекурсивных грамматик в выводе А + А всегда либо, либо. Если = и =, то грамматика G является циклической грамматикой. Пример Примером праворекурсивной грамматики является грамматика со следующей схемой: 1 0 Данная грамматика порождает множество чисел, состоящих из нулей и единиц.

Пример Тот же самый язык, что и в примере порождает леворекурсивная грамматика со следующей схемой: 1 0

Пример Примером леворекурсивной грамматики является грамматика со следующей схемой: А 1 0 Данная грамматика порождает множество идентификаторов, начинающихся с буквы А.

Пример Тот же самый язык, что и в примере порождает праворекурсивная грамматика со следующей схемой: А 1 0

Лемма 10.1 Пусть G = (N, P, S) – КС-грамматика, в которой для некоторого нетерминального символа А все А- правила имеют вид А A 1 | A 2 | … | A m | 1 | 2 | … | n | причем ни одна из цепочек i не начинается с А. Пусть G"=(N {A"}, P", S), где A" – новый нетерминал, а P" получается из P заменой этих А- правил следующими правилами А 1 | 2 | … | n | 1A" | 2A" | … | nA" | А" 1 | 2 | … | m | 1A" | 2A" | … | mA" Тогда L(G") = L(G). Рассмотрим алгоритм преобразования КС- грамматики, в которой имеется непосредственная левая рекурсия, к КС-грамматике без левой рекурсии.

Доказательство. Цепочки, которые можно получить в грамматике G из нетерминала А применением А- правил лишь к самому левому нетерминалу, образуют регулярное множество (… + n)(… + m)* Это в точности те цепочки, которые можно получить в грамматике G" из А с помощью правых выводов, применив один раз А-правило и несколько раз А"- правила (в результате вывод уже не будет левым). Все шаги вывода, на которых не используются А- правила, можно непосредственно сделать и в грамматике G", так как не А-правила в обеих грамматиках одни и те же. Отсюда можно заключить, что L(G) L(G").

Обратное включение доказывается аналогично. В грамматике G" берется правый вывод и рассматриваются последовательности шагов, состоящие из одного применения А-правила и нескольких применений А"-правил. Таким образом, L(G") = L(G). Грамматика примера получена из грамматики примера с использованием преобразования леммы 10.1.

Лемма 10.2 Пусть G = (N, P, S) – КС-грамматика, в которой для некоторого нетерминального символа А все А- правила имеют вид А A 1 | A 2 | … | A m | 1 | 2 | … | m причем ни одна из цепочек i не начинается с А. Пусть G"=(N, P", S), где P" получается из P заменой этих А-правил следующими правилами А 1 | 2 | … | m | 1A | 2A | … | mA Тогда L(G") = L(G). Грамматика примера получена из грамматики примера с использованием преобразования леммы 10.2.

На рисунке показано, как действуют преобразования на дерево вывода A A i1... i2 A A ik A ik A ik-1... i1

Пример Пусть G0 – обычная грамматика с правилами E E+T E T T T*F T F F (E) F a Эквивалентная ей грамматика G`

E T E TE" E" +T E" +TE" T F T FT " T " *F T " *FT " F (E) F a Рассмотрим теперь, как преобразовать приведенную леворекурсивную КС-грамматику к КС-грамматике, не имеющей левой рекурсии.

Алгоритм 10.2 Устранение левой рекурсии. Вход: Приведенная КС-грамматика G=(N,P,S) Выход: Эквивалентная КС-грамматика G` без левой рекурсии. Метод. Пусть N = {A1,…, An}, т.е. все нетерминальные символы грамматики упорядочены некоторым произвольным образом. Преобразуем G так, чтобы в правиле Ai цепочка начиналась либо с терминала, либо с такого Aj, что j i. 1) Положим i=1.

2) Пусть множество Ai – правил – это Ai Ai | … | Ai m | 1 | … | p, где ни одна из цепочек j не начинается с Ak, если k i (если это не выполнено, можно ввести новый нетерминальный символ, заменить первый символ правила этим символом и добавить дополнительное правило в грамматику). Заменим Ai–правила правилами: Ai 1 | … | p | 1Ai" | … | pAi" Ai" 1 | … | m | 1Ai" | … | mAi" где A"i новый нетерминал. Правые части всех Ai- правил начинаются теперь с терминала или с Ak для некоторого k > i. 3) Если i=n, полученную грамматику G" считать результатом и остановиться. В противном случае положить i=i+1 и j=1.
i. 3) Если i=n, полученную грамматику G" считать результатом и остановиться. В противном случае положить i=i+1 и j=1.">

J, то и правая часть каж" title="4) Заменить каждое правило вида Ai Aj правилами Ai 1 |…| m, полученными в результате замены Aj правыми частями всех Aj-правил вида Aj 1|…| m. Так как правая часть каждого Aj-правила начинается уже с терминала или с Ak для k > j, то и правая часть каж" class="link_thumb"> 16 4) Заменить каждое правило вида Ai Aj правилами Ai 1 |…| m, полученными в результате замены Aj правыми частями всех Aj-правил вида Aj 1|…| m. Так как правая часть каждого Aj-правила начинается уже с терминала или с Ak для k > j, то и правая часть каждого Ai- правила будет теперь обладать этим свойством. 5) Если j=i–1, перейти к шагу (2). В противном случае положить j=j+1 и перейти к шагу (4). j, то и правая часть каж"> j, то и правая часть каждого Ai- правила будет теперь обладать этим свойством. 5) Если j=i–1, перейти к шагу (2). В противном случае положить j=j+1 и перейти к шагу (4)."> j, то и правая часть каж" title="4) Заменить каждое правило вида Ai Aj правилами Ai 1 |…| m, полученными в результате замены Aj правыми частями всех Aj-правил вида Aj 1|…| m. Так как правая часть каждого Aj-правила начинается уже с терминала или с Ak для k > j, то и правая часть каж"> title="4) Заменить каждое правило вида Ai Aj правилами Ai 1 |…| m, полученными в результате замены Aj правыми частями всех Aj-правил вида Aj 1|…| m. Так как правая часть каждого Aj-правила начинается уже с терминала или с Ak для k > j, то и правая часть каж">
Теорема 10.1 Для каждого КС-языка существует порождающая его не леворекурсивная грамматика. Доказательство есть следствие приведенных в данном разделе преобразований. Пример Пусть G есть КС-грамматика с правилами A BC a B CA Ab C AB CC a

Положим A1=A, A2=B и A3=C После каждого применения шага (2) или (4) алгоритма получаются следующие грамматики (указываем только новые правила). Шаг (2) для i=1: G не меняется Шаг (4) для i=2, j=1: B CA BCb ab Шаг (2) для i=2: B CA ab CAB abB B Cb Шаг (4) для i=3, j=1: C BCB aB CC a Шаг (4) для i=3, j=2: C CACB ab CB CAB CB ab B CB aB CC a Шаг (2) для i=3: C abCB ab B CB aB a abCBC ab B CB C aB C aC C ACB C AB CB C CC ACB AB CB C



Рис. 4.4.
начинающейся с и продолжающейся упомянутыми k терминалами.
Грамматика называется LL (k)-грамматикой, если она LL (k)- грамматика для некоторого k .
Пример 4.7 . Рассмотрим грамматику G = ({S, A, B}, {0, 1, a, b}, P, S) , где P состоит из правил
S -> A | B, A -> aAb | 0, B -> aBbb | 1.
Здесь . G не является LL (k)-грамматикой ни для какого k. Интуитивно, если мы начинаем с чтения достаточно длинной цепочки, состоящей из символов a , то не знаем, какое из правил S -> A и S -> B было применено первым, пока не встретим 0 или 1 .
Обращаясь к точному определению LL (k)-грамматики, положим и y = a k 1b 2k . Тогда выводы

соответствуют выводам (1) и (2) определения. Первые k символов цепочек x и y совпадают. Однако заключение ложно. Так как k здесь выбрано произвольно, то G не является LL -грамматикой.
Следствия определения LL(k)- грамматики
Теорема 4.6
. КС-грамматика
является LL(k)-грамматикой тогда и только тогда, когда для двух
различных правил
и из Р
пересечение
пусто при всех таких
,
что
![]() .
.
Доказательство . Необходимость . Допустим, что и удовлетворяют условиям теоремы, а содержит x . Тогда по определению FIRST для некоторых y и z найдутся выводы

(Заметим, что здесь мы использовали тот факт, что N не содержит бесполезных нетерминалов, как это предполагается для всех рассматриваемых грамматик.) Если |x| < k ; то y = z = e . Так как , то G не LL (k)- грамматика .
Достаточность . Допустим, что G не LL (k)- грамматика .
Тогда найдутся такие два вывода
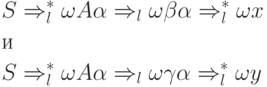
что цепочки x
и y
совпадают в первых k позициях, но . Поэтому и - различные правила из P
и каждое
из множеств ![]() и
и ![]() содержит цепочку FIRST k (x)
, совпадающую с цепочкой FIRST k (y)
.
содержит цепочку FIRST k (x)
, совпадающую с цепочкой FIRST k (y)
.
Пример 4.8 . Грамматика G , состоящая из двух правил S -> aS | a , не будет LL (1)-грамматикой, так как
FIRST 1 (aS) = FIRST 1 (a) = a .
Интуитивно это можно объяснить так: видя при разборе
цепочки, начинающейся символом a
, только этот первый символ,
мы не знаем, какое из правил S -> aS
или S -> a
надо применить
к S
. С другой стороны, G
- это LL
(2)- грамматика
. В самом деле, в
обозначениях только что представленной теоремы, если ![]() , то A = S
и . Так как для S
даны только два указанных правила, то и . Поскольку FIRST2(aS) = aa
и FIRST2(a) = a
, то по
последней теореме G
будет LL
(2)-грамматикой.
, то A = S
и . Так как для S
даны только два указанных правила, то и . Поскольку FIRST2(aS) = aa
и FIRST2(a) = a
, то по
последней теореме G
будет LL
(2)-грамматикой.
Удаление левой рекурсии
Основная трудность при использовании предсказывающего анализа - это нахождение такой грамматики для входного языка, по которой можно построить таблицу анализа с однозначно определенными входами. Иногда с помощью некоторых простых преобразований грамматику, не являющуюся LL(1), можно привести к эквивалентной LL(1)-грамматике. Среди этих преобразований наиболее эффективными являются левая факторизация и удаление левой рекурсии . Здесь необходимо сделать два замечания. Во-первых, не всякая грамматика после этих преобразований становится LL(1), и, во-вторых, после таких преобразований получающаяся грамматика может стать менее понимаемой.
Непосредственную левую рекурсию, то есть рекурсию вида , можно удалить следующим способом. Сначала группируем A -правила:
где никакая из строк не начинается с A . Затем заменяем этот набор правил на
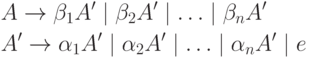
где A" - новый нетерминал. Из нетерминала A можно вывести те же цепочки, что и раньше, но теперь нет левой рекурсии . С помощью этой процедуры удаляются все непосредственные левые рекурсии , но не удаляется левая рекурсия, включающая два или более шага. Приведенный ниже алгоритм 4.8 позволяет удалить все левые рекурсии из грамматики.
Алгоритм 4.8 . Удаление левой рекурсии .
Вход . КС-грамматика G без e-правил (вида A -> e ).
Выход . КС-грамматика G" без левой рекурсии , эквивалентная G .
Метод . Выполнить шаги 1 и 2.
(1) Упорядочить нетерминалы грамматики G в произвольном порядке.
(2) Выполнить следующую процедуру:

После (i-1)
-й итерации внешнего цикла на шаге 2 для
любого правила вида ![]() , где k < i
, выполняется s > k
.
В результате на следующей итерации (по i
) внутренний цикл
(по j
) последовательно увеличивает нижнюю границу по m
в
любом правиле
, где k < i
, выполняется s > k
.
В результате на следующей итерации (по i
) внутренний цикл
(по j
) последовательно увеличивает нижнюю границу по m
в
любом правиле ![]() , пока не будет m >= i
. Затем, после удаления непосредственной левой рекурсии
для A i
-правил, m
становится больше i
.
, пока не будет m >= i
. Затем, после удаления непосредственной левой рекурсии
для A i
-правил, m
становится больше i
.
При процедуре рекурсивного разбора сверху вниз может возникнуть проблема бесконечного цикла.
В грамматике для арифметических операций применение второго правила приведет к зацикливанию процедуры разбора. Подобные грамматики называются леворекурсивными. Грамматика называется леворекурсивной, если в ней существует нетерминал А, для которого существует вывод А=>+Аa. В простых случаях левая рекурсия вызвана правилами вида
В этом случае вводят новый нетерминал и исходные правила заменяют следующими.
(если есть нетерминал А, для которого существует вывод А→+Аa за 1 или более шагов). Левой рекурсии можно избежать, преобразовав грамматику.
Например, продукции A→Aa
Можно заменить на эквивалентные:
Для такого случая существует алгоритм, исключающий левую рекурсию:
1) определяем на множестве нетерминалов какой-либо порядок (А 1 , А 2 , …, А n)
2) берем каждый нетерминал, если для него есть продукция, учитывающая нетерминал, стоящий левее, и преобразуем грамматику:
for i:=1 to n do
for j:=1 to i-1 do
if Ai → Ajγ then Ai→δ1γ
│ δkγ, где
Aj → δ1│ δ2│ …│ δk
3) исключаем все случаи непосредственной левой рекурсии (правило1)
Т.о. алгоритм помогает избежать зацикливания.
Исключение левой рекурсии из грамматики арифметических выражений и общий вид правила исключения левой рекурсии:
Общий вид правила исключения левой рекурсии
Левая факторизация.
LL(1)-грамматики нужны для того, чтобы выбрать нужную продукцию для разбора сверху-вниз, чтобы не произошло зацикливание.
Иногда существует возможность преобразовать грамматику к LL(1) виду, используя метод левой факторизации.
Например: S→ if B then S
│if B then S else S
Эти продукции нарушают условие LL(1)-грамматик. Эту грамматику можно преобразовать к виду LL(1).
S → if B then S Tail
В общем виде это преобразование можно определить так:
вводим новый нетерминал В, для которого
| β N Для B можно применить левую факторизацию. Эта процедура повторяется, пока остается неопределенным выбор продукции (т.е. пока в ней можно что-нибудь изменить).
Построение множества FIRST
Множество First для нетерминала определяет множество терминалов, с которых может начинаться данный нетерминал.
1. Если х - терминал, то first(x)={x}. Так как первым символом последовательности из одного терминала может являться только сам терминал.
2. Если в грамматике присутствует правило Хà e, то множество first(х) включает e. Это означает, что Х может начинаться с пустой последовательности, то есть отсутствовать вообще.
3. Для всех продукций вида XàY1 Y2 … Yk выполняем следующее. Добавляем в множество first(Х) множество first(Yi) до тех пор, пока first(Yi-1) содержит e, а first(Yi) не содержит e. При этом i изменяется от 0 до k. Это необходимо, так как если Yi-1 может отсутствовать, то необходимо выяснить, с чего будет начинаться вся последовательность в этом случае.
(Время: 1 сек. Память: 16 Мб Сложность: 20%)В теории формальных грамматик и автоматов (ТФГиА) важную роль играют так называемые контекстно-свободные грамматики (КС-грамматики). КС-грамматикой будем называть четверку, состоящую из множества N нетерминальных символов, множества T терминальных символов, множества P правил (продукций) и начального символа S, принадлежащего множеству N.
Каждая продукция p из P имеет форму A –> a , где A нетерминальный символ (A из N), а a – строка, состоящая из терминальных и нетерминальных символов. Процесс вывода слова начинается со строки, содержащей только начальный символ S. После этого на каждом шаге один из нетерминальных символов, входящих в текущую строку, заменяется на правую часть одной из продукций, в которой он является левой частью. Если после такой операции получается строка, содержащая только терминальные символы, то процесс вывода заканчивается.
Во многих теоретических задачах удобно рассматривать так называемые нормальные формы грамматик. Процесс приведения грамматики к нормальной форме часто начинается с устранения левой рекурсии. В этой задаче мы будем рассматривать только ее частный случай, называемый непосредственной левой рекурсией. Говорят, что правило вывода A –> R содержит непосредственную левую рекурсию, если первым символом строки R является A.
Задана КС-грамматика. Требуется найти количество правил, содержащих непосредственную левую рекурсию.
Входные данные
Первая строка входного файла INPUT.TXT содержит количество n (1 ≤ n ≤ 1000) правил в грамматике. Каждая из последующих n строк содержит по одному правилу. Нетерминальные символы обозначаются заглавными буквами английского алфавита, терминальные - строчными. Левая часть продукции отделяется от правой символами –>. Правая часть продукции имеет длину от 1 до 30 символов.
Особенность формальных грамматик в том, что они позволяют определить бесконечное множество цепочек языка с помощью конечного набора правил (конечно, множество цепочек языка тоже может быть конечным, но даже для простых реальных языков это условие обычно не выполняется). Приведенная выше в примере грамматика для целых десятичных чисел со знаком определяет бесконечное множество целых чисел с помощью 15 правил.
Возможность пользоваться конечным набором правил достигается в такой форме записи грамматики за счет рекурсивных правил. Рекурсия в правилах грамматики выражается в том, что один из нетерминальных символов определяется сам через себя. Рекурсия может быть непосредственной (явной) - тогда символ определяется сам через себя в одном правиле, либо косвенной (неявной) - тогда то же самое происходит через цепочку правил.
В рассмотренной выше грамматике G непосредственная рекурсия присутствует в правиле: <чс>-»<чс><цифра>, а в эквивалентной ей грамматике G" - в правиле: T-VTF.
Чтобы рекурсия не была бесконечной, для участвующего в ней нетерминального символа грамматики должны существовать также и другие правила, которые определяют его, минуя самого себя, и позволяют избежать бесконечного рекурсивного определения (в противном случае этот символ в грамматике был бы просто не нужен). Такими правилами являются <чс>-»<цифра> - в грамматике G и T->F -в грамматике G".
В теории формальных языков более ничего сказать о рекурсии нельзя. Но, чтобы полнее понять смысл рекурсии, можно прибегнуть к семантике языка - в рассмотренном выше примере это язык целых десятичных чисел со знаком. Рассмотрим его смысл.
Определение грамматики. Форма ьэкуса-маура «ЗО /
Если попытаться дать определение тому, что же является числом, то начать можно с того, что любая цифра сама по себе есть число. Далее можно заметить, что л юбые две цифры - это тоже число, затем - три цифры и т. д. Если строить определение числа таким методом, то оно никогда не будет закончено (в математике разрядность числа ничем не ограничена). Однако можно заметить, что каждый раз, порождая новое число, мы просто дописываем едифру справа (поскольку привыкли писать слева направо) к уже написанному ряду цифр. А этот ряд цифр, начиная от одной цифры, тоже в свою очередь является числом. Тогда определение для понятия «число» можно построить таким образом: «число - это любая цифра, либо другое число, к которому справа дописана любая цифра». Именно это и составляет основу правил грамматик G и G" и отражено во второй строке правил в правилах <чс>-><цифра> [ <чс><цифра> и Т->F | TF. Другие правила в этих грамматиках позволяют добавить к числу знак (первая строка правил) и дают определение понятию «цифра» (третья строка правил). Они элементарны и не требуют пояснений.
Принцип рекурсии (иногда его называют «принцип итерации», что не меняет сути) - важное понятие в представлении о формальных грамматиках. Так или иначе, явно или неявно рекурсия всегда присутствует в грамматиках любых реальных языков программирования. Именно она позволяет строить бесконечное множество цепочек языка, и говорить об их порождении невозможно без понимания принципа рекурсии. Как правило, в грамматике реального язык? программирования содержится не одно, а целое множество правил, построенных с помощью рекурсии.
Другие способы задания грамматик
Форма Бэкуса-Наура - удобный с формальной точки зрения, но не всегда доступный для понимания способ записи формальных грамматик. Рекурсивные определения хороши для формального анализа цепочек языка, но не удобны с точки зрения человека. Например, то, что правила <чс>-><цифра> | <чс><цифра> отражают возможность для построения числа дописывать справа любое число цифр, начиная от одной, неочевидно и требует дополнительного пояснения.
Но при создании языка программирования важно, чтобы его грамматику понимали не только те, кому предстоит создавать компиляторы для этого языка, но и пользователи языка - будущие разработчики программ. Поэтому существуют Другие способы описания правил формальных грамматик, которые ориентированы на большую понятность человеку.
Запись правил грамматик
с использованием метасимволов
Запись правил грамматик с использованием метасимволов предполагает, что в строке правила грамматики могут встречаться специальные символы - мета-
358 Глава 9. Формальные языки и грамматики
Символы, - которые имеют особый смысл и трактуются специальным образом. В качестве таких метасимволов чаще всего используются следующие символы: () (круглые скобки), (квадратные скобки), {} (фигурные скобки), «,» (запятая) и "" (кавычки). Эти метасимволы имеют следующий смысл:
□ круглые скобки означают, что из всех перечисленных внутри них цепочек
символов в данном месте правила грамматики может стоять только одна це
почка;
□ квадратные скобки означают, что указанная в них цепочка может встречать
ся, а может и не встречаться в данном месте правила грамматики (то есть мо
жет быть в нем один раз или ни одного раза);
□ фигурные скобки означают, что указанная внутри них цепочка может не встре
чаться в данном месте правила грамматики ни одного раза, встречаться один
раз или сколь угодно много раз;
□ запятая служит для того, чтобы разделять цепочки символов внутри круглых
скобок;
□ кавычки используются в тех случаях, когда один из метасимволов нужно
включить в цепочку обычным образом - то есть когда одна из скобок или за
пятая должны присутствовать в цепочке символов языка (если саму кавычку
нужно включить в цепочку символов, то ее надо повторить дважды - этот
принцип знаком разработчикам программ).
Вот как должны выглядеть правила рассмотренной выше грамматики G, если их записать с использованием метасимволов:
<число> -» [(+.-)]<цифра>{<цифра>}
<цифра> ->0|1|2|3|4|5|6|7|8|9
Вторая строка правил не нуждается в комментариях, а первое правило читается так: «число есть цепочка символов, которая может начинаться с символов + или -, должна содержать дальше одну цифру, за которой может следовать последовательность из любого количества цифр». В отличие от формы Бэкуса-Наура, в форме записи с помощью метасимволов, как видно, во-первых, убран из грамматики малопонятный нетерминальный символ <чс>, а во-вторых - удалось полностью исключить рекурсию. Грамматика в итоге стала более понятной.
Форма записи правил с использованием метасимволов - это удобный и понятный способ представления правил грамматик. Она во многих случаях позволяет полностью избавиться от рекурсии, заменив ее символом итерации {} (фигурные скобки). Как будет понятно из дальнейшего материала, эта форма наиболее употребительна для одного из типов грамматик - регулярных грамматик.
Запись правил грамматик в графическом виде
При записи правил в графическом виде вся грамматика представляется в форме набора специальным образом построенных диаграмм. Эта форма была предложена при описании грамматики языка Pascal, а затем она получила широкое распространение в литературе. Она доступна не для всех типов грамматик, а только
Определение грамматики. Форма Бэкуса-Наура 359
Для контекстно-свободных и регулярных типов, но этого достаточно, чтобы ее можно было использовать для описания грамматик известных языков программирования.
В такой форме записи каждому нетерминальному символу грамматики соответствует диаграмма, построенная в виде направленного графа. Граф имеет следующие типы вершин:
□ точка входа (на диаграмме никак не обозначена, из нее просто начинается
входная дуга графа);
□ нетерминальный символ (на диаграмме обозначается прямоугольником, в ко
торый вписано обозначение символа);
□ цепочка терминальных символов (на диаграмме обозначается овалом, кругом
или прямоугольником с закругленными краями, внутрь которого вписана це
почка);
□ узловая точка (на диаграмме обозначается жирной точкой или закрашенным
кружком);
□ точка выхода (никак не обозначена, в нее просто входит выходная дуга графа).
Каждая диаграмма имеет только одну точку входа и одну точку выхода, но сколько угодно вершин других трех типов. Вершины соединяются между собой направленными дугами графа (линиями со стрелками). Из входной точки дуги могут только выходить, а во входную точку - только входить. В остальные вершины дуги могут как входить, так и выходить (в правильно построенной грамматике каждая вершина должна иметь как минимум один вход и как минимум один выход).
Чтобы построить цепочку символов, соответствующую какому-либо нетерминальному символу грамматики, надо рассмотреть диаграмму для этого символа. Тогда, начав движение от точки входа, надо двигаться по дугам графа диаграммы через любые вершины вплоть до точки выхода. При этом, проходя через вершину, обозначенную нетерминальным символом, этот символ следует поместить в результирующую цепочку. При прохождении через вершину, обозначенную цепочкой терминальных символов, эти символы также следует поместить в результирующую цепочку. При прохождении через узловые точки диаграммы над результирующей цепочкой никаких действий выполнять не надо. Через любую вершину графа диаграммы, в зависимости от возможного пути движения, можно пройти один раз, ни разу или сколь угодно много раз. Как только мы попадем в точку выхода диаграммы, построение результирующей цепочки закончено.
Результирующая цепочка, в свою очередь, может содержать нетерминальные символы. Чтобы заменить их на цепочки терминальных символов, нужно, опять же, рассматривать соответствующие им диаграммы. И так до тех пор, пока в цепочке не останутся только терминальные символы. Очевидно, что для того, чтобы построить цепочку символов заданного языка, надо начать рассмотрение с Диаграммы целевого символа грамматики.
Это удобный способ описания правил грамматик, оперирующий образами, а потому ориентированный исключительно на людей. Даже простое изложение его основных принципов здесь оказалось довольно громоздким, в то время как суть
Глава 9. формальные языки и i рамматики
Способа довольно проста. Это можно легко заметить, если посмотреть на описание понятия «число» из грамматики G с помощью диаграмм на рис. 9.1.
Рис. 9.1. Графическое представление грамматики целых десятичных чисел со знаком: вверху - для понятия «число»; внизу - для понятия «цифра»
Как уже было сказано выше, данный способ в основном применяется в литературе при изложении грамматик языков программирования. Для пользователей - разработчиков программ - он удобен, но практического применения в компиляторах пока не имеет.
Классификация языков и грамматик
Выше уже упоминались различные типы грамматик, но не было указано, как и по какому принципу они подразделяются на типы. Для человека языки бывают простые и сложные, но это сугубо субъективное мнение, которое зачастую зависит от личности человека.
Для компиляторов языки также можно разделить на простые и сложные, но в данном случае существуют жесткие критерии для этого разделения. Как будет показано далее, от того, к какому типу относится тот или иной язык программи-
Рования, зависит сложность распознавателя для этого языка. Чем сложнее язык, тем выше вычислительные затраты компилятора на анализ цепочек исходной программы, написанной на этом языке, а следовательно, сложнее сам компилятор и его структура. Для некоторых типов языков в принципе невозможно построить компилятор, который бы анализировал исходные тексты на этих языках за приемлемое время на основе ограниченных вычислительных ресурсов (именно поэтому до сих пор невозможно создавать программы на естественных языках, например на русском или английском).
Классификация грамматик.


